�����������B�W�g���ṩ��
���O�����ҵ������е�ijһ�����ӡ������һ�һ퓵�������������@�����ܕr�g����ͨ�^ʹ�ñ���������������Ժܿ���ҵ���Ҫ���������}�����������c����һ��������������dz����ơ������ԘO�����߲�ԃ���ٶȡ���һ���^��ı���f��ͨ�^��������һ��ͨ��Ҫ���M�ׂ�С�r����ɵIJ�ԃֻҪ��犾Ϳ�����ɡ�
��˛]�����Ɍ���Ҫ�l����ԃ�ı�����������
ע�⣺
����ăȴ�������Ӳ�P���g����r��Ҳ�S�㲻��oһ�����������������ڰ��������Ĕ����죬SQL Sever ��Ҫһ�����^���~����g�����磬Ҫ����һ���۴���������Ҫ��s��.�����ڔ�����С�Ŀ��g��Ҫ��һ��һ�����������ڔ���������ռ�Ŀ��g��С�������ʹ��ϵ�y�惦�^��sp_spaceused��������ָ���鱻�����ı�����
�۴������ͷǾ۴������������������B��
���O���ѽ�ͨ�^�����������ҵ���һ���������ڵ�퓴a��һ���ѽ�֪����퓴a����ܿ������oĿ�ķ����@������ֱ���ҵ����_��퓴a��ͨ�^�S�C�ķ���������K���Ե��_���_��퓴a�����ǣ���һ�N�ҵ�퓴a�ĸ���Ч�ķ�����
���ȣ��ѕ��������һ��ĵط������Ҫ�ҵ�퓴a�Ȱ뱾��̎��퓴aС���͕������ķ�֮һ̎����t���Ͱѕ������ķ�֮���ĵط���ͨ�^�@�N������������^�m�ѕ��ֳɸ�С�IJ��֣�ֱ���ҵ����_��퓴a�������@���ҵ���퓵ķdz���Ч��һ�N������
SQL Sever �ı���������Ƶķ�ʽ������һ����������һ�M퓽M�ɣ��@Щ퓘�����һ�����νY�������ͨ�^ָ������ɂ�퓣���һ������ӛ䛏�߉�Ϸֳɺ̓ɂ����֡��������ָ��ăɂ���ַքe��ӛ䛷ָ�ɸ�С�IJ��֡�ÿ��퓶���ӛ䛷ֳɸ�С�ķֱָ�����_�~��퓡�
�����ЃɷN��ͣ��۴������ͷǾ۴��������ھ۴������У���������~��퓰������H�Ĕ�����ӛ䛵���������c���������ͬ���ڷǾ۴������У��~���ָ����е�ӛ䛣�ӛ䛵���������c߉���]�б�Ȼ��ϵ��
�۴������dz���Ŀ䛱���Ŀ䛱�������c���H��퓴a�����һ�µġ��Ǿ۴������t������Ę˜����������������е����ͨ���c���H��퓴a����Dz�һ�µġ�һ����Ҳ�S�ж������������磬��Ҳ�Sͬ�r�����}����������������ͬ�ӣ�һ���������ж����Ǿ۴�������ͨ����r�£���ʹ�õ��Ǿ۴������������㑪ԓ���ɷN��������ă�ȱ�c���������⡣ÿ����ֻ����һ���۴����������һ�����е�ӛ�ֻ����һ�N��������š�ͨ����Ҫ��һ���������R�ֶν����۴����������ǣ���Ҳ���Ԍ�������͵��ֶν����۴����������ַ��ͣ���ֵ�ͺ����ڕr�g���ֶΡ��Ľ����˾۴������ı���ȡ������Ҫ�Ƚ����˷Ǿ۴������ı��졣������Ҫȡ��һ�������ȵĔ����r���þ۴�����Ҳ���÷Ǿ۴������á����磬���O����һ�����ӛ��L��������W�c�ϵĻ�ӡ��������ȡ����һ���r�g�ȵĵ����Ϣ���㑪ԓ���@������DATETIME ���ֶν����۴�������
���۴���������Ҫ������ÿ����ֻ�ܽ���һ���۴����������ǣ�һ���������в�ֹһ���Ǿ۴����������H�ϣ���ÿ�����������Խ���249���Ǿ۴���������Ҳ���Ԍ�һ����ͬ�r�����۴������ͷǾ۴��������������������B��
�����㲻�H��������ڣ�����������Ñ�������ľW�c�����־��ȡ���������@�N��r�£�ͬ�r����һ���۴������ͷǾ۴���������Ч�ġ�����Ԍ����ڕr�g�ֶν����۴����������Ñ����ֶν����Ǿ۴������������l�F����Ҫ�����������ʽ����������Ӹ���ķǾ۴�������
�Ǿ۴�������Ҫ������Ӳ�P���g�̓ȴ档���⣬�mȻ�Ǿ۴�����������ߏı��� ȡ�������ٶȣ���Ҳ����������в�����������ٶȡ�ÿ�����׃��һ�������˷Ǿ۴������ı��еĔ����r�����ͬ�r��������������㌦һ���������Ǿ۴������rҪ���ؿ��]��������AӋһ������Ҫ�l���ظ���������ô��Ҫ��������̫��Ǿ۴����������⣬���Ӳ�P�̓ȴ���g���ޣ�Ҳ��ԓ����ʹ�÷Ǿ۴������Ĕ�����
��������
�@�ɷN��͵��������Ѓɂ���Ҫ���ԣ�������Ã�������һ�N���ͬ�r�������ֶν����������ͺ����������ɷN��͵�����������ָ����Ψһ������
����Ԍ������ֶν���һ���ͺ������������Ǐͺϵľ۴�������������һ����ӛ�����ľW�c�L���ߵ��պ����֡������ϣ���������������ı���ȡ����������Ҫ����һ��ͬ�r�����ֶκ������ֶ��M�е��������@�ͷքe���ɂ��ֶν����Ϊ��������Dz�ͬ�ġ�����ϣ��ͬ�r����ֹһ���ֶ��M�в�ԃ�r���㑪ԓ����һ���������ֶε������������ϣ���������ֶ��M�зքe��ԃ���㑪ԓ�����ֶν����������������������������B��
�ɷN��͵����������Ա�ָ����Ψһ�����������һ���ֶν�����Ψһ�������㌢�������@���ֶ�ݔ���؏͵�ֵ��һ�����R�ֶΕ��Ԅӳɞ�Ψһֵ�ֶΣ�����Ҳ���Ԍ�������͵�
�ֶν���Ψһ���������O����һ�����������ľW�c���Ñ��ܴa���㮔Ȼ��ϣ���ɂ��Ñ�����ͬ���ܴa��ͨ�^����һ���ֶγɞ�Ψһֵ�ֶΣ�����Է�ֹ�@�N��r�İl����
��SQL��������
���˽oһ�������������������΄ՙ�SQL Sever ����M�е�ISQL/w �����M���ԃ��
�ں�ݔ��������Z�䣺
CREATE INDEX mycolumn_index ON mytable (myclumn)
�@���Z�佨����һ������mycolumn_index ������������Խoһ���������κ����֣����㑪ԓ���������а������������ֶ������@���㌢��Ū�������ԓ��������D���Ў����ġ�
ע�⣺
�ڱ�����������κ�SQL�Z�䣬�����յ����µ���Ϣ��
This command did not return data,and it did not return any rows
�@�f��ԓ�Z����гɹ��ˡ�
����mycolumn_index����mytable ��mycolumn�ֶ��M�С��@�ǂ��Ǿ۴�������Ҳ�ǂ���Ψһ���������@��һ��������ȱʡ���ԣ��������Ҫ��׃һ����������ͣ����횄h��ԭ�����������ؽ� һ����������һ����
����������������SQL �Z��h������
DROP INDEX mytable.mycolumn_index
ע����DROP INDEX �Z������Ҫ�����������֡����@�������У���h����������
mycolumn_index�����DZ�mytable ��������
Ҫ����һ���۴�����������ʹ���P�I��CLUSTERED����ӛסһ����ֻ����һ���۴�������
���@����һ����Ό�һ���������۴����������ӣ��������������B��
CREATE CLUSTERED INDEX mycolumn_clust_index ON mytable(mycolumn)
����������؏͵�ӛ䛣�����ԇ�D���@���Z�佨�������r�������F�e�`���������؏�ӛ䛵ı�Ҳ���Խ�����������ֻҪʹ���P�I��ALLOW_DUP_ROW���@һ�c���VSQL Sever ���ɣ�
CREATE CLUSTERED INDEX mycolumn_cindex ON mytable(mycolumn)
WITH ALLOW_DUP_ROW
�@���Z�佨����һ�����S�؏�ӛ䛵ľ۴��������㑪ԓ�M��������һ�����г��F�؏�ӛ䛣����ǣ�����ѽ����F�ˣ������ʹ���@�N������
Ҫ��һ��������Ψһ����������ʹ���P�I��UNIQUE�����۴������ͷǾ۴�����������ʹ���@���P�I�֡��@����һ�����ӣ�
CREATE UNIQUE COUSTERED INDEX myclumn_cindex ON mytable(mycolumn)
�@���㌢����ʹ�õ����������Z�䡣�oՓ�Εr��ֻҪ���ԣ��㑪ԓ�M����һ����һ��������Ψһ�۴�������������ԃ���������Ҫ����һ���������ֶε����������ͺ��������������������Z����ͬ�r���������ֶ�������������ӌ�firstname ��lastname�ɂ��ֶν���������
CREATE INDEX name_index ON username(firstname,lastname)
�@�����ӌ��ɂ��ֶν����ˆ���������һ���ͺ������У��������Ԍ�16 ���ֶ��M
��������
һ. �ۼ�����B������������������B��
����1.�ۼ�������B��Y���M�нM���ģ�����B��N��ÿһ퓷Q��һ���������c��B���픶˹��c�Q������c��
���������еĵ͌ӹ��c�Q���~���c�������c�c�~���c֮�g���κ��������e�y�Q�����g�����ھۼ������У��~���c�������A���Ĕ���퓡�
���������c�����g�����c�������������е�����퓡�ÿ�������а���һ���Iֵ��һ��ָᘣ�ԓָ�ָ�� B ���ϵ�ijһ���g��퓻��~�������е�ij��������.ÿ�������е�퓾����B�����p��朽��б��С�
����2.����ʹ�õ�ÿһ���օ^��index_id = 1 ��Ĭ�J��r�¾ۼ��������օ^����ʹ�÷օ^���ĕr��ÿ���օ^����һ������ԓ�ض��օ^���P������B��Y���������@ô����IJ�֪��������?
����3.SQL Server ����Ĕ���������會ȵ�퓺��Ќ����ۼ������Iֵ�M������
����4.SQL Server ���������в���ԓ��������ʼ�Iֵ��Ȼ������ǰ������ڔ�������M�В��衣���˲��Ҕ����朵���퓣�SQL Server ���������ĸ����c������߅��ָ��M�В��衣
�����ۼ�����B��D ��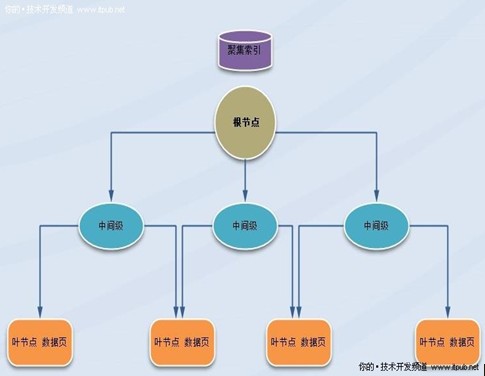
�� .���� Transact-SQL �Z�佛��ʹ�õ��Z�� �������������B��
����1.SET STATISTICS IO {ON| OFF} /*Transact-SQL �Z�����ɵĴűP���������Ϣ*/
����2.SET SHOWPLAN_ALL ON {ON| OFF} /*�������P�Z�������r��Ԕ����Ϣ������Ӌ�Z�䌦�YԴ������*/
����3.SET STATISTICS TIME {ON| OFF} /*�@ʾ���������g�͈��и��Z������ĺ��딵*/
����4.ʹ��T-SQL�Z�䄓���������Z����
CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED]
����INDEX index_name
����ON table_name (column_name)
����[WITH FILLFACTOR=x]
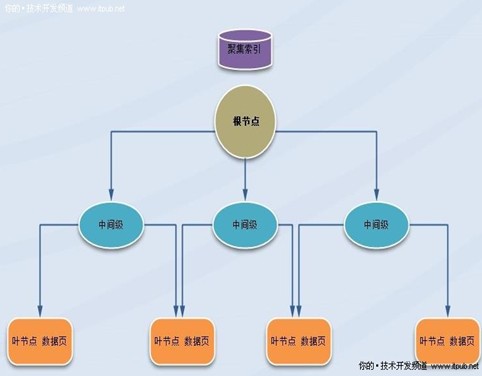
����һ. �ۼ�����B�����
����1.�ۼ�������B��Y���M�нM���ģ�����B��N��ÿһ퓷Q��һ���������c��B���픶˹��c�Q������c��
���������еĵ͌ӹ��c�Q���~���c�������c�c�~���c֮�g���κ��������e�y�Q�����g�����ھۼ������У��~���c�������A���Ĕ���퓡�
���������c�����g�����c�������������е�����퓡�ÿ�������а���һ���Iֵ��һ��ָᘣ�ԓָ�ָ�� B ���ϵ�ijһ���g��퓻��~�������е�ij��������.ÿ�������е�퓾����B�����p��朽��б��С�
����2.����ʹ�õ�ÿһ���օ^��index_id = 1 ��Ĭ�J��r�¾ۼ��������օ^����ʹ�÷օ^���ĕr��ÿ���օ^����һ������ԓ�ض��օ^���P������B��Y���������@ô����IJ�֪��������?
����3.SQL Server ����Ĕ���������會ȵ�퓺��Ќ����ۼ������Iֵ�M������
����4.SQL Server ���������в���ԓ��������ʼ�Iֵ��Ȼ������ǰ������ڔ�������M�В��衣���˲��Ҕ����朵���퓣�SQL Server ���������ĸ����c������߅��ָ��M�В��衣�������������B��
�����ۼ�����B��D ��
������ .���� Transact-SQL �Z�佛��ʹ�õ��Z��
����1.SET STATISTICS IO {ON| OFF} /*Transact-SQL �Z�����ɵĴűP���������Ϣ*/
����2.SET SHOWPLAN_ALL ON {ON| OFF} /*�������P�Z�������r��Ԕ����Ϣ������Ӌ�Z�䌦�YԴ������*/
����3.SET STATISTICS TIME {ON| OFF} /*�@ʾ���������g�͈��и��Z������ĺ��딵*/
����4.ʹ��T-SQL�Z�䄓���������Z����
CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED]
����INDEX index_name
����ON table_name (column_name)
����[WITH FILLFACTOR=x]
�� ���������yԇ������W������Փ֪�R�������������B��
--������
CREATE TABLE employee
(
emp_username varchar (20),
emp_register DATETIME
)
--����yԇ����
DECLARE @startid INT
DECLARE @endid INT
SELECT @startid= 1,@endid = 100
WHILE @startid <=@endid
BEGIN
INSERT INTO employee (
emp_username,
emp_register
) VALUES (
/* emp_username - varchar (20) */ '��'+CAST(@startid AS NVARCHAR(20)),
/* emp_register - DATETIME */ GETDATE() )
SELECT @startid =@startid +1;
END
-- ��ԃemployee�Ĉ���Ӌ�� �� io ��Ϣ
SET STATISTICS IO ON
SELECT * FROM employee WHERE emp_username = '��'
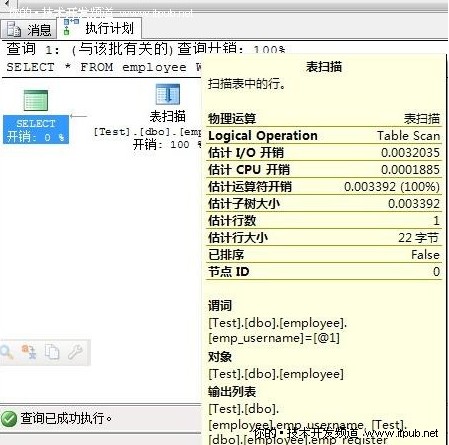
�鿴��Ϣݔ���� IO ��Ϣ
������'employee'��(1)1����Ӌ��1��(2)߉�xȡ1 �Σ�(3)�����xȡ0 �Σ�(4)�A�x0 �Σ�lob ߉�xȡ0 �Σ�lob �����xȡ0 �Σ�lob �A�x0 �Ρ�
����ݔ������Ϣ������ĈDƬ�v����nj�����
����1. ���еĒ���Δ� ��
����2. �ĴűP�xȡ��퓔���
����3. ���M�в�ԃ�����뾏���퓔���
����4. �A�x
����T_SQL transaction �Z���кܶ�N�Č��������ǛQ���Ǘl�Z��������Ǹ���(logical reads) ߉�xȡ���Дࡣ�������������B��
�������Ӿۼ����� ��ԃ߉�xȡ�Ƿ��׃��
CREATE CLUSTERED INDEX Idx_emp_username ON employee (emp_username);
--Ȼ���و��в�ԃ
SET STATISTICS IO ON
SELECT * FROM employee WHERE emp_username = '��'
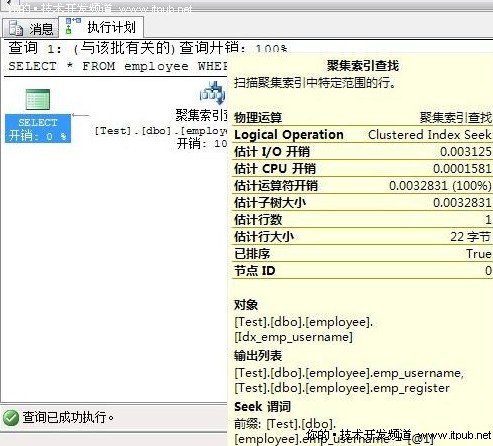
�鿴��Ϣݔ���� IO ��Ϣ
������'employee'������Ӌ��1��߉�xȡ2 �Σ������xȡ0 �Σ��A�x0 �Σ�lob ߉�xȡ0 �Σ�lob �����xȡ0 �Σ�lob �A�x0 �Ρ�
����Q �@��߉�xȡ��2�Ξ�ʲô�� ?
����A.�y����ԃ�ȱ����߀Ҫ�������nj��ģ�������С�ĕr�ۼ������ă����w�F��������
����Q ��ʲô��2��߉�xȡ
����A �F�ڲ�ԃ�ĕr����ۼ������D���Ȳ�ԃ����� �����ҵ��������Iֵ���蔵��퓣�����а���������ֱ��������퓾Ϳ�����ȡ����Ҫ�Ĕ�����
���������f��С�������ĕr��ۼ������w�F����Ч���������҂��^�m��䔵���yԇ ��
�������yԇ������1000
���������
������Ϣ��
������'employee'������Ӌ��1��߉�xȡ36 �Σ������xȡ0 �Σ��A�x0 �Σ�lob ߉�xȡ0 �Σ�lob �����xȡ0 �Σ�lob �A�x0 �Ρ�
�����ۼ���������
������Ϣ��
������'employee'������Ӌ��1��߉�xȡ2 �Σ������xȡ0 �Σ��A�x0 �Σ�lob ߉�xȡ0 �Σ�lob �����xȡ0 �Σ�lob �A�x0 �Ρ�
�����@���r��ۼ������ă��ݾ����@ʾ������ O(��_��)O
���������ځ��v�vtransaction sql �Z�� ������ھW�Ͽ�����һЩ���f In like left ��ʹ������ ���҂����ց�yԇ�¿������f�Č����� ?
�����h��employee��������
DROP INDEX employee.Idx_emp_username
�������_IO��Ϣ�������������B��
SET STATISTICS IO ON
SELECT * FROM employee WHERE employee.emp_username in ('��10000')
��Ϣ��
������ 'employee'������Ӌ�� 1��߉�xȡ 371 �Σ������xȡ 0 �Σ��A�x 0 �Σ�lob ߉�xȡ 0 �Σ�lob �����xȡ 0 �Σ�lob �A�x 0 �Ρ�
--����Idx_emp_username�ۼ�����
CREATE CLUSTERED INDEX Idx_emp_username ON employee (emp_username);
SELECT * FROM employee WHERE employee.emp_username in ('��10000');
��Ϣ:
������ 'employee'������Ӌ�� 1��߉�xȡ 3 �Σ������xȡ 0 �Σ��A�x 0 �Σ�lob ߉�xȡ 0 �Σ�lob �����xȡ 0 �Σ�lob �A�x 0 �Ρ�
����ʹ��������߉�xȡ3�Σ��]��ʹ��������371�Σ�IN �ܺõ�ʹ��������!
���������҂���yԇ�� LIKE �Ƿ�ܺõ�ʹ������
�����h������
DROP INDEX employee.Idx_emp_username
�������_IO ��Ϣ
SET STATISTICS IO ON
�������в�ԃ
SELECT * FROM employee WHERE employee.emp_username like ('��1000%')
��Ϣ��
������ 'employee'������Ӌ�� 1��߉�xȡ 371 �Σ������xȡ 0 �Σ��A�x 0 �Σ�lob ߉�xȡ 0 �Σ�lob �����xȡ 0 �Σ�lob �A�x 0 �Ρ�
������������
CREATE CLUSTERED INDEX Idx_emp_username ON employee (emp_username);
SET STATISTICS IO ON
SELECT * FROM employee WHERE employee.emp_username like ( '��1000%');
������ 'employee'������Ӌ�� 1��߉�xȡ 3 �Σ������xȡ 0 �Σ��A�x 0 �Σ�lob ߉�xȡ 0 �Σ�lob �����xȡ 0 �Σ�lob �A�x 0 �Ρ�
�����W�Ϻܶ���������������ԃ��Ҫʹ�� in like left ���䌍�Լ����֜yԇ�¿�����ԃӋ����һĻ��Ȼ���������������B��




